
There's a version of this topic that gets written a lot. It opens with a claim about the future of robotics, cycles through some impressive-sounding terminology, and lands on a product. This isn't that version.
What follows is an explanation of what machine learning is actually doing inside a modern bin picking system — what problems it solves, why those problems are hard, where the approach breaks down, and what separates a research demo from something that runs in a factory. If you're newer to the topic, this field guide covers the fundamentals before getting into the ML side of things.
A few terms appear throughout this article and are worth pinning down. Machine learning (ML) is a subset of AI — where instead of writing explicit rules, you train a system on examples and let it figure out the patterns. Neural networks are the underlying model structure that makes this work: they're what gets trained, and what runs during production. In practice, the industry uses "AI vision," "AI bin picking," and "physical AI" to refer to the same underlying technology.
The two problems a bin picking system has to solve
Before getting into what ML does, it helps to be clear about the structure of the problem.
A bin picking system has two distinct jobs.
- First, vision: figuring out where the parts are, what orientation they're in, and where the robot should grip or suction.
- Second, motion: planning and executing the physical movement towards the part, picking it, and placing it at the destination.
Machine learning can, in principle, apply to both. In practice, the case for ML is much stronger on the vision side.
For motion planning, classical methods have decades of development behind them, they're well understood, and they perform reliably in production. Applying ML to motion in bin picking tends to introduce complexity without a clear payoff.
Why classical vision hits a wall
Classical vision relies on hand-engineered rules. For a given part, a vision engineer crafts an algorithm: detect edges with these parameters, look for contours that match this shape, verify the geometry is within this tolerance. The problem is how fragile it tends to be.
The rules that work under one set of conditions often break under slightly different ones. Move the cell to a location with different ambient lighting, and the system may fail entirely. Introduce a part with a slightly different surface finish, and the contour detection may not recognize it. Adjusting the rules to handle the new condition risks breaking behavior that was already working. And because the rules encode the engineer's specific model of what the part looks like, debugging and improving them requires that same engineer's involvement every time.

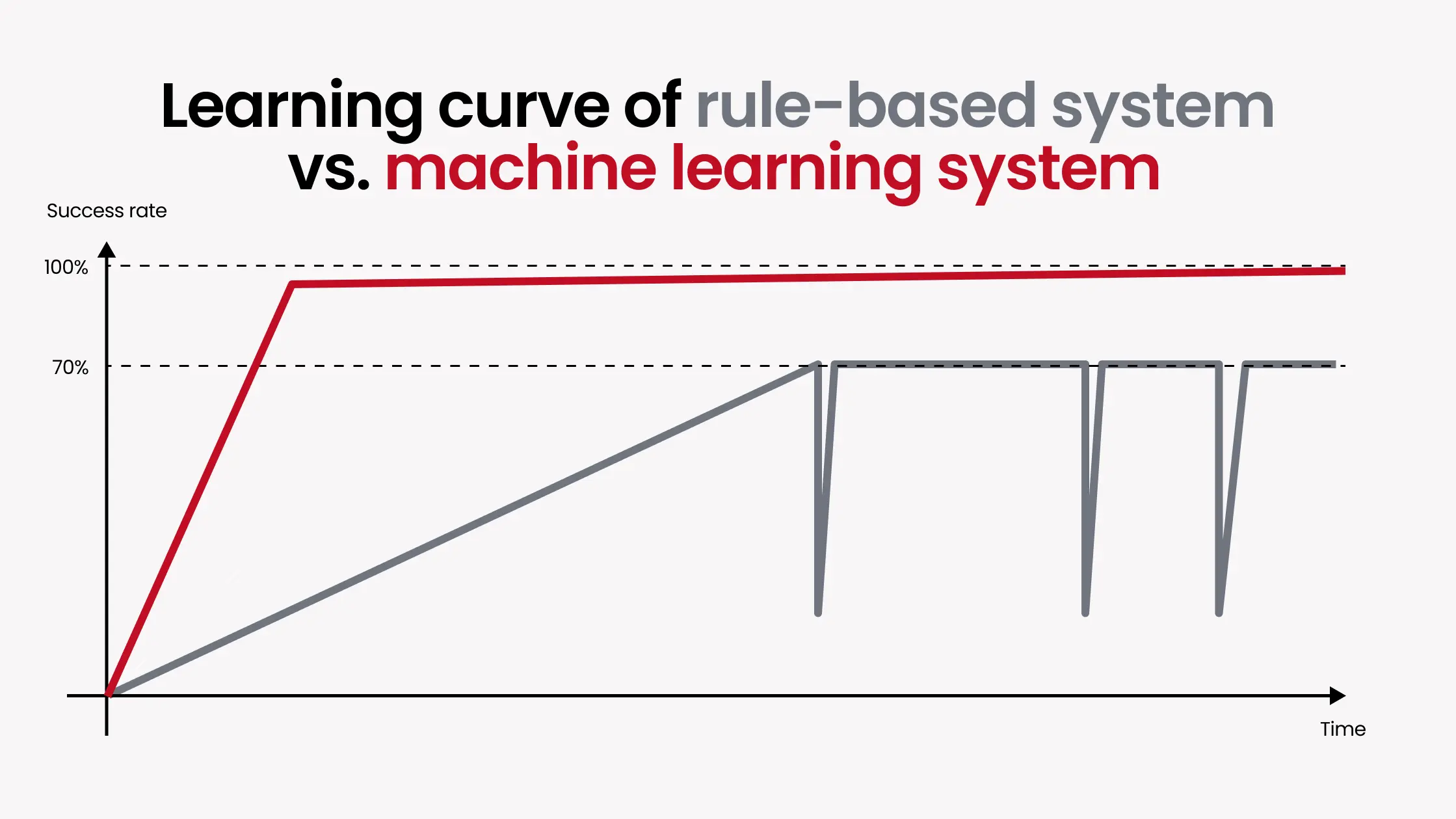
In many real deployments, classical vision systems plateau around a 70% success rate for complex parts, and pushing beyond that becomes difficult or impossible.
What ML-based vision actually does differently
ML-based vision approaches the problem from the other direction. Instead of an engineer specifying what a part looks like, the system learns it from examples.
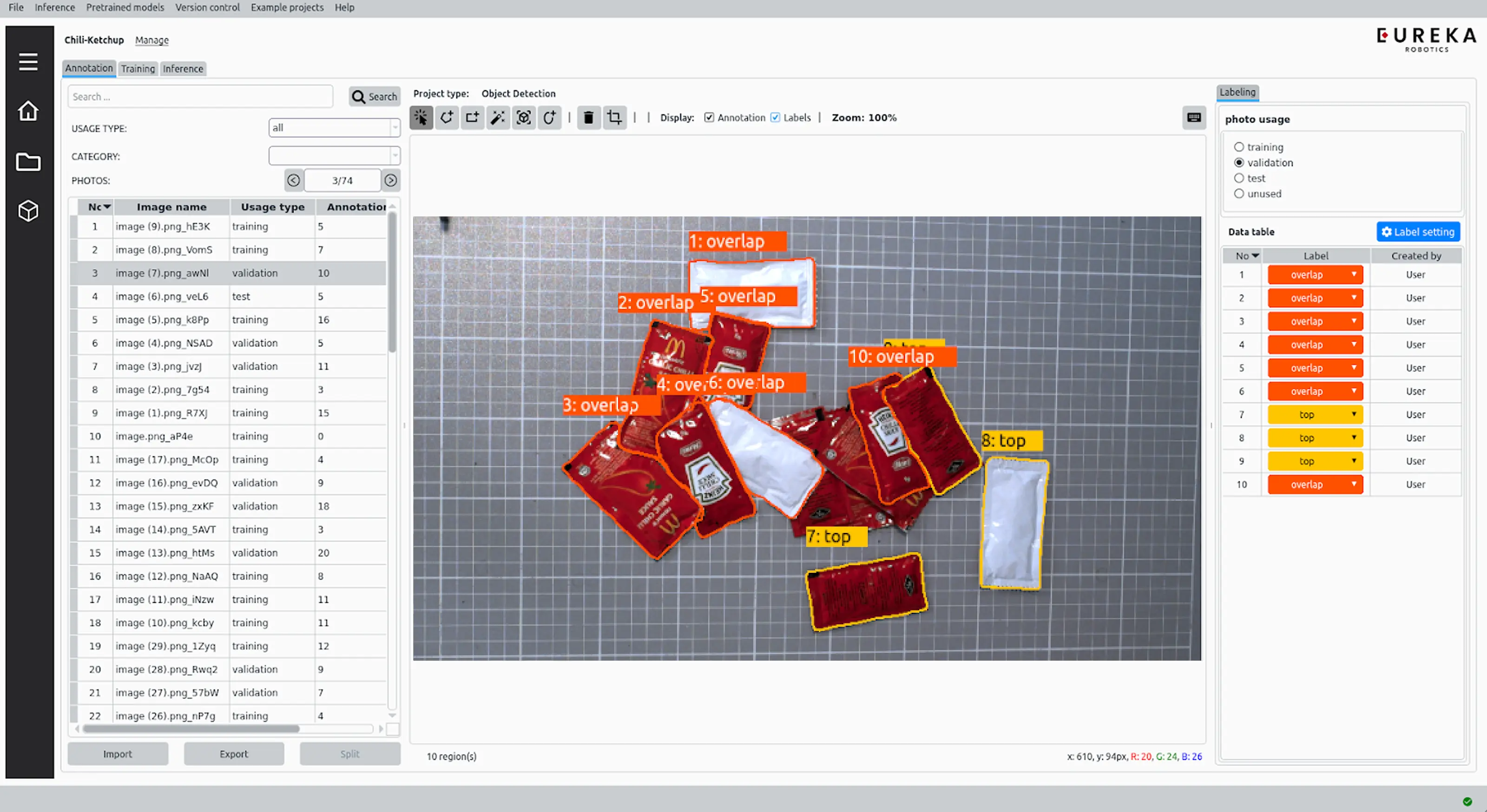
The process: take photos of the part in realistic conditions, annotate them to indicate where the parts are and how they're oriented, and train a neural network on that dataset. Increasingly, and this is the direction we're pushing, simulated data and automatic annotation replace the manual photography and labeling steps entirely. Either way, the network learns the underlying structure, what features consistently appear when a part is in a given position, rather than relying on brittle geometric rules.
The practical results are meaningful. Systems using ML-based vision routinely reach 98–99.9% success rates on parts where classical vision couldn't reliably get past 70%. They handle lighting variation better because you can include scenes with different lighting in the training data, both physically captured and simulated. When they encounter a failure, improving the model is often a matter of adding the failed case to the training dataset and retraining, which takes minutes. The new model handles not just that specific failure but similar cases it hasn't encountered before.
This doesn't mean ML vision is without limits. For metrology, precision dimensional measurement, it's not the right tool. In those applications, the better approach is to use ML vision to determine part location and orientation, then apply classical methods for the measurement itself. Knowing where ML helps and where it doesn't is part of using it well.
How training actually works in production
A common assumption is that setting up ML bin picking for a new part requires thousands of images and weeks of training. That's not how modern production systems work.
At Eureka Robotics, we start from a foundational model pretrained on millions of data points, across a wide range of parts and environments. When deploying on a new part, we fine-tune from this foundation model using a small dataset — typically 20 to 30 images. That's enough to achieve robust production performance, because the foundational model already understands a great deal about what industrial objects look like and how to pick them.
For parts with standard geometries that tend to present in predictable orientations, this approach is straightforward. For parts with complex geometries that can appear in any orientation — a metallic hook tumbling in a bin (see video below), for example — photography alone doesn't cover the space of possible positions. This is the full-3D random bin picking problem, and it's where 3D-matching-based training comes in. Given a 3D model of the part, we render it across tens of thousands of simulated positions and orientations, generating synthetic training images that cover the full range of how the part might present. If the customer has CAD data they can share, that's the starting point. If not, we build the 3D model from a physical sample.
A system that improves over time
One of the more underappreciated aspects of ML-based vision is what happens after deployment. Classical vision systems are largely static — improving them without causing regressions elsewhere is genuinely difficult. ML systems are not.
When an ML-based system encounters a part it fails to detect, adding that failure case to the training dataset and retraining takes minutes. The new model handles that scenario correctly going forward, and generalizes to similar cases it hasn't seen before. Beyond customer-specific retraining, we also push regular software updates through an Annual Maintenance Contract — improvements to model architectures and curated datasets that benefit all customers, delivered as opt-in updates. Every update brings measurable gains in speed or failure rate.
What happens when the system fails a pick
Failures in bin picking don't always originate in the vision system, and it's worth knowing how to tell the difference.
When a pick fails, there are two distinct possibilities: the ML proposed a bad pick point, or it proposed a good one that the robot failed to execute — a calibration error or a mechanical failure like a suction cup not seating properly. We address this by overlaying the proposed pick point on a visualization of the scene — a digital twin. If the proposed point looks wrong in the visualization, the issue is in the ML. If it looks correct but the robot still fails, the problem is elsewhere.
This is also where ML shows one of its more underappreciated advantages over classical vision. A failed pick isn't just a problem to fix — it's a teaching opportunity. With a classical rules-based system, the opposite risk exists: adjusting the rules to account for a new failure case can break behavior that was already working. The more complex the part, the worse this problem tends to get.
What to ask a vendor who claims ML bin picking
If you're evaluating systems and a vendor claims ML- or AI-based bin picking, a few questions will quickly reveal whether the claim is substantive.
How do you train the system for a new SKU — do you need CAD data, annotated images, and how many? Can the system handle a new part that's similar to an existing one (same shape, different size) without starting from scratch? What happens when lighting changes in the cell — does it require retraining? Can training run on the local controller, or does it require a cloud connection?
The answers will tell you whether you're looking at a genuine production system or a controlled demo.
The gap between research and what runs in a factory
Production bin picking systems are not simply running the latest published ML research. Perhaps 99% of academic work in robotics and AI — including significant portions of our own team's prior academic output — never makes it into production. The models that perform well in controlled conditions don't automatically transfer to factory environments.
The work that goes into bridging that gap includes the user interface that lets non-expert users collect images, annotate parts, and train models. It includes the data pipeline for managing large datasets while keeping customer part data private. It includes the server architecture for running multiple concurrent training jobs. And it includes the edge inference system that communicates in real time with the camera and the robot. You can learn more about how we've built this out in our AI vision software for bin picking.
The models matter. But they're only part of what makes a system production-ready.
Eureka Robotics builds vision-guided bin picking systems for industrial automation, with over 30 million picks in production across customers including Pratt & Whitney, Toyota, Denso, and Sumitomo.